

Gary Marcus's Response to My Critique of His AI Views
Marcus's Rebuttal to My Recent Post on Generative AI and Its Future--Unedited


Hi everyone,
After my recent critique of Gary Marcus’s views on generative AI,
responded directly with a thoughtful and pointed reply. He clarifies where he feels misrepresented and expands on the key issues at stake. I’m sharing his unedited response here—an insightful addition to the heated debate about AI’s trajectory and future impact.I’m happy to share this exchange. We’re both critics of the status quo, and while mainstream AI often speaks with one voice, critics speak with many—something I believe is to our credit. Though I’m not responding here, I encourage readers to weigh in, particularly on the central question: how best should we critique AI today?
…………………………………………………………………………………………….
Here’s his response, unedited:
Dear Erik,
I was surprised by your recent Substack for a number of reasons.
To start with, you seemed to attribute to me the belief that LLMs will literally disappear (by saying “LLMs are [still] here”. I have never said that, but rather said literally the opposite. For example, I recently wrote “ To be sure, Generative AI itself won’t disappear. But investors may well stop forking out money at the rates they have, enthusiasm may diminish, and a lot of people may lose their shirts”
I stand by that.
For over 30 years I have argued for integrating neural networks (of which LLMs are the most popular current example) with classic symbolic AI. My argument has never been to dismiss deep learning altogether, but rather to use it as a part of a larger toolkit. Here’s one of the many places I made the clear, back in 2018:
Despite all of the problems I have sketched, I don't think that we need to abandon deep learning. Rather, we need to reconceptualize it: not as a universal solvent, but simply as one tool among many, a power screwdriver in a world in which we also need hammers .. and pliers, not to mentions chisels and drills, voltmeters, logic probes, and oscilloscopes.
DeepMind’s recent success with hybrid models such as AlphaFold, AlphaGeometry, and AlphaProof all stand in testament for the value of integrated approaches.
I have certain argued that “generative AI may turn out to be a dud” financially, and that companies like OpenAI may see their valuations drop dramatically. And I have argued that hallucinations and boneheaded errors aren’t going anywhere until we develop new architectures.
But even I expect LLMs to continue to exist; what’s at issue is whether they will have the impact that people like Altman have implied.
As a side note, you seem to characterize me an alarmist, but I only sound some bells but not others. I have argued that the possibility of extinction is quite low, and challenged some of Hariri’s projections of AI-driven financial chaos, for example.
On some other issues, I think you have adjudicated too soon. It’s clear that high-volume misinformation, was part of the US election, and public trust has been greatly undermined. Of course causality is hard to discern. But it may have been more potent that people are widely acknowledging. Quoting the economist Brad DeLong recently argued “Misinformation decided US election. Polling data show that Donald Trump’s supporters were deeply misinformed about most of the campaign’s defining issues.”. Meanwhile cybercrime is up from all the informal data I can gather, and the US government reported that AI was used by foreign actors. We can expect more of this to come. (And indeed, the legal battles have multiplied, just I projected; we all know these things will take years to resolve.) We are only (at most) two years into this and for many things (misinformation, discrimination, cybercrime etc) don’t even have measures yet. I wouldn’t say we are out of the woods yet.
Another issue that you perhaps misread, though it is very much open, is OpenAI’s health. Yes they did get a new round of funding (with Apple dropping out at the last minute) but they also continue face pretty serious headwinds, many of which I have written about. Their relationship with Microsoft is fraying, many staff have left, they have not in fact released GPT-5 or Sora, competitors are catching up, they burning an enormous amount of cash, and they still have no obvious tech moat. I still don’t see a clear scenario in which they become long-term profitable with so many competitors and so little that is unique. WeWork’s valuation rose and rose until it didn’t. We’ll see.
Just in the week since you wrote your essay, the mood of the field has very much swung towards supporting my longstanding prediction about GenAI’s diminishing returns, with numerous articles reporting Andreesen, Sutskever, and LeCun all basically saying LLMs are hitting a wall. That’s not great news for OpenAI, if Google, Anthropic, and Meta all catch up.
Lastly, I have written 250 blog posts in the last two years, and I feel that in addition to strawmanning some of my claims, you were also pretty selective. My main predictions for 2024, expressed in a Substack post but more concisely in a tweet, for example, were dead on, and I don’t think you gave me credit for any.
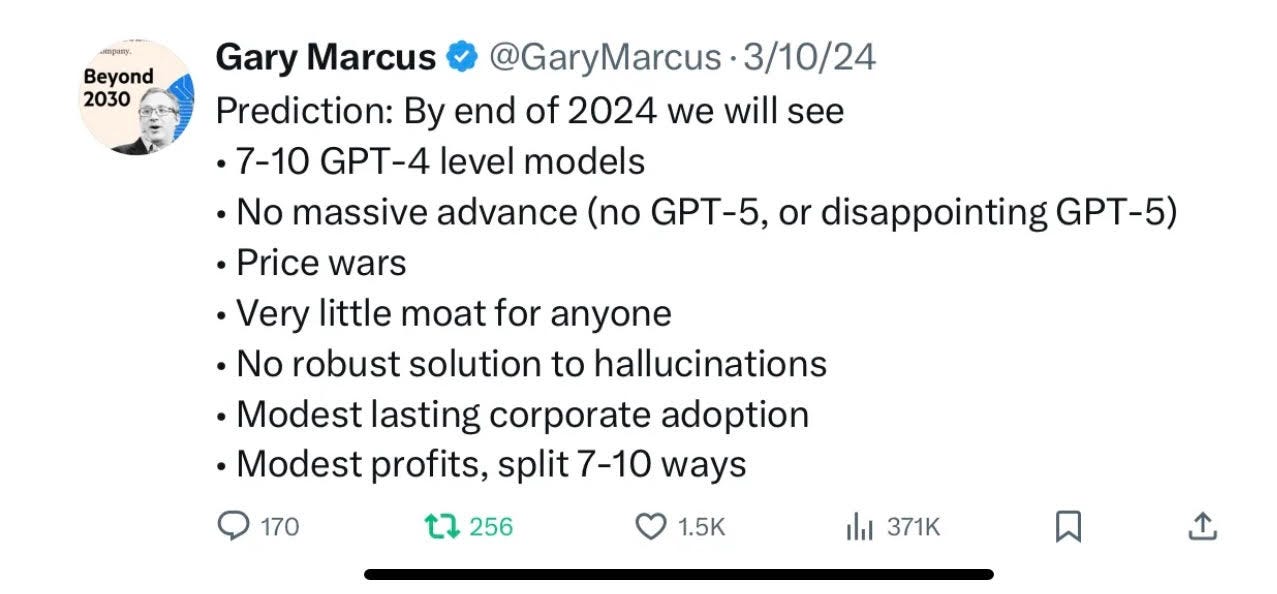
Putting all together, I just don’t think your essay was fair. I appreciate your offer to let me respond.
Gary
The most substantive part of your critique is that the world hasn’t fallen apart. Nobody said that it would take exactly a year, and many of the processes I was concerned about about our in fact of underway, but we lack clear data.
Wonderful that Mr Marcus responded.
Also curious that I was bothered by the typos. Very authentically human, though.
What I keep finding confounding is that Mr Marcus keeps pushing a “I was right all along” narrative. For my taste, there is too much “I” and too much about being right in this.
Who needs to be saved here, and from what? Investors who are pouring money into AI, mostly manifesting in the form of LLMs? Let them do what they like. We could simply assume, they are smart, or hire smart people to vet their investments.
Also, more pedantically and technically speaking, why can’t we focus more on what we actually know? It is Nov, 18th, so… how can we know what is or is not going to happen until the end of the year? Maybe OpenAI will release their next model. That is still what they say they plan on.
As for the “wall”, there is more than one take on this. For one, the quoted people are merely saying that naive scaling of pre-training may no longer be the best way to scale. But then there is inference time compute and that has definitely an effect.
See https://www.linkedin.com/posts/peter-gostev_i-was-watching-a-talk-by-the-nvidia-ceo-and-activity-7264031391821008897-Ii9c
Some (fairly smart) people say that o1-preview marks a crude start to, and is a paradigm shift.
And as we discussed recently somewhere here in the context of Erik’s post, overall, there are many people who are getting a ton of value out of LLM technology – in its current state.
OpenAI is also not LLMs. After all, while pretty ambitious, they aim to build AGI. If THAT is going to work out, is a much more consequential and much more speculative question. We might live to see.
If Mr Marcus turns out to be right, I am just not sure what has been gained.
If people approach LLM technology with a healthy dose of understanding how it’s working, what its inherent limitations are, and are curious about how to further explore its capabilities, we might just get somewhere, as in: why not embark on a constructive and productive journey instead of repetitively pointing out that it won’t work.
Here’s where I’d challenge Mr Marcus:
"For over 30 years I have argued for integrating neural networks (of which LLMs are the most popular current example) with classic symbolic AI. "
OK, so just build it. How hard can it be? Since you are maybe THE expert on this particular perspective, and its OG, and you have a huge following, how difficult is it really to work on that, get some funding or however you want to go about doing it?
I mean, LLM tech is being pushed forward very rapidly. So that half of your problem is solved by the very mechanism you are criticizing. Just take the fruits of that “fool’s errand”, leverage the falling cost ("price wars” you predicted), and work on that neurosymbolic combo. Let’s go.
Then post some updates about progress and how you are going to build powerful AI that is actually reasoning and all that.
You made your point. Time to build.
I would say that discussions about any AI/LLM wall, and especially an “AGI/commonsense wall,” have to be based on a closer look at and a far better understanding of the brain and perception, i.e., why the brain is so entirely different from an AI/computer. Take a simple event like “stirring coffee with a spoon.” In the framework of ecological psychology (that of J. J. Gibson) the event is described by invariance laws – it has an “invariance structure.” Here’s a partial list:
• A radial flow field (an array of velocity vectors) defined over the swirling liquid
• An adiabatic invariant carried over a haptic flow field re the spoon, i.e., a ratio of energy of oscillation to frequency of oscillation (Kugler, 1987).
• An inertial tensor defining the various momenta of the spoon, and specific to the spoon’s constant length and mass (Turvey & Carello, 1995, 2011).
• Acoustical invariants
• Constant ratios relative to texture gradients (the table surface, the cup as it turns) and flows for the form and size constancy of the cup and the cup (or eye) moves over the surface,
• A ratio (“tau”, the time derivative of the inverse of the relative rate of optical expansion) related to our grasping of the cup (Savelsbergh et al., 1991).
• And more…
•
Note, this is multi-modal event; the invariants are amodal – they are coordinate across modalities as the event is ongoing – the acoustical clinking/frequency changes are coordinate with adiabatic change, with the inertial change, and on – an intrinsic “binding” of all aspects of the event.
The brain’s response (with its integral tie to the body’s systems for action) to this event, where the invariants are preserved over time, over the continuously changing event (a continuity, note, which is NOT a mathematically dense continuity of points, instants, “states”) – this response Gibson was forced to view under a “resonance” metaphor – the brain resonating, also continuously, to this structure, and “specific to” or “specifying” the perceived, external, ongoing, coffee stirring event.
This invariance structure underlies our knowledge of “coffee stirrings,” and of course our understanding of sentences, e.g., “The man stirred the coffee with the spoon.” How this event structure is “stored” in the brain is a massive problem, but the word-vector spaces of the LLM’s are obviously nothing like this event – they bear no resemblance to this dynamic structure - in effect being but an extremely ramped-up version of 18th century associationism. Inertial tensors, adiabatic invariants are not going to be stored in a vector space.
AI hallucinations, from this perspective, seem another variant of the frame problem. We are stirring the coffee and suddenly the coffee liquid rises up in a column, say, two inches above the cup’s rim, then falls back, then another “pulse” back up two inches, then down... For a robot, is this pulsing column an expected event while stirring coffee? In the symbolic AI world, this was once considered a matter of checking one’s frame axioms – the huge list of things remaining unchanged during the event, e.g., the cup’s form, the spoon’s length, the kitchen floor’s stability, the current president of the US… For the human, this liquid-pulsing event will simply not “resonate” with the all the rest of our [stored] experience of coffee stirrings. It is an instant, felt dissonance (yes, an intrinsic intentionality). ChatGPT, however, will likely “solve” this too, if asked, “Is something wrong here?” via its vector space (one can imagine the answer!). But what if its training set contained enough sentences/docs containing whimsical descriptions of coffee stirring events with pulsing coffee columns? This would be incorporated as part of the AIs coffee stirring “knowledge,” but this knowledge is obviously not anything like the human, ecological experience (knowledge) of coffee stirring, with all its forces, etc.
This is near the core of the LLM problem with commonsense, but it is just the beginning of the differences if one takes a closer look at the science of perception; it is much worse. AI is actually marching blithely along with no theory whatsoever on the origin of our image of the external world – the coffee cup “out there,” spoon stirring (a time-extended perception). That is, AI has (and thinks it needs) no theory of perception. Ever-changing bits in a computer is not a model of how we have an image of the external world. Gibson says the brain is “specifying” the event, is “specific to” the event. But what this means is far from the same as the computer model or anything the computer model could do (an article on this “specification” in the journal, Ecological Psychology, 2023 – “Gibson and Time”). This is ultimately an enormous difference underlying the “knowledge” structure of AI vs. humans, and the origin of the image problem is foundational to the operation of our imagination – another thing AI feels it can do without.
Then there is the problem of the brain’s specification of a scale of time – at our normal scale, a “buzzing” fly, winging past the coffee cup, wings ablur. But this is just one of many possible scales of time at which the external matter-field can be specified. How about a “heron-like fly,” slowly flapping his wings (and concomitantly the coffee swirls slow down, the spoon circles more slowly, a drinking glass gets more vibrant, conversation slows…). This has been hypothesized to be the bio-chemical effect of LSD – for note, the brain is indeed a bio-chemical mass, and this is routinely ignored by the AI/computational metaphor (another article: in the journal, Psychology of Consciousness, 2022 – “LSD and perception”). Imagine the difference implied for the nature of the “device” that the human is vs. the computer/AI. Would an LLM now have to have a vector space for every possible scale of time?
In any case, these are just few of the problems, and critics like Gary Marcus are simply not conversant with (it seems) or dealing with this dimension. That’s my two cents.