

Gerben Wierda on ChatGPT, Altman, and the Future
Gerben Wierda, one of the top IT professionals in Europe, guest posts on Colligo.

Hi All,
The world is atwitter right now with the conflict between Sam Altman and the board of OpenAI. Gary Marcus is posting about it almost daily, and the ink getting spilled over it is considerable, and for good reason. On Colligo, we too are “following the story.” It’s my honor to publish a wonderful guest post from Gerben Wierda, who can put the Altman shocker in a broader and helpful context. Gerben recently gave a talk about ChatGPT on YouTube that’s attracted considerable attention—please do check it out. It’s worth it. Gerben is a Lead Architect for APG — a not-for-profit fiduciary / collective pension fund manager that manages ~600 billion euros and the pensions of ~4.5 million participants. He occasionally speaks at conferences, publishes a blog and has written two well-received IT books. Wonderful to have him on Colligo.
Thanks Erik, and great to be guest posting on Colligo. As you know, I really loved your book, and continue to follow the work you’re doing. It’s my pleasure to share my thoughts — which, I must stress, are my own and not APG's — with your readers. I hope everyone enjoys.
Understanding Large Language Models Remains Important
Sam Altman has been dismissed by the board of the non-profit that owns OpenAI. The latest on the grapevine seems to indicate that there is a conflict between the lofty goals — create safe and beneficial human-level AI for the world — of the non-profit OpenAI Inc. and the goals of the commercial sub-venture OpenAI LLC — which is there to make money, and which allows for commercial investors such as Microsoft to participate. It looks like Sam is looking for ways to escape the remaining constraints of the lofty non-profit. A new restructuring that turns the tables — the commercial sub venture becoming the lead and the not-for-profit lofty one simply becoming subsidised by the commercial arm — seems a possible outcome. Frankly, everybody is guessing now and so am I.
Both goals, the lofty ones of OpenAI Inc, and the monetary ones of OpenAI LLC assume that we're on the road to Artificial General Intelligence (human-like or above-human-like AI) with what OpenAI and others have been doing. That assumption runs deep with Sam and his fellows at OpenAI — as well as the rest of the world that is experiencing a certain 'ChatGPT-fever'.
To illustrate, Altman was recently at Cambridge University (UK) to receive a 'Hawking Fellowship' for the OpenAI team. This session has been published on YouTube, and after a short speech, Altman goes into a question and answer session with the public. Altman's contributions in that session — and others over the last year — have been confusing. Altman agreed that 'new breakthroughs' were required to get to 'AGI' (Artificial General Intelligence — the AI level that is equivalent to human intelligence). But at the same time, his remarks were full of high expectations, up to and beyond AGI into the level of 'superintelligence'. My take from listening closely was: there is a lot of confusion, fuzziness and contradiction in what he says, maybe he is simply out of his depth. After all, at some point he predicts abundant free fusion energy that is around the corner and even larger models as a result. Altman being out of his depth is not weird: we humans tend to conflate success with 'being right', but that relation is far less strong than we assume.
When — during that Hawking Fellowship session — Sam Altman was asked about what qualities founders of innovative firms should have, he answered that founders should have ‘deeply held convictions’ that are stable without a lot of ‘positive external reinforcement’, ‘obsession’ with a problem, and a ‘super powerful internal drive’. They needed to be an 'evangelist'.
But simply relying on often repeated assumptions is risky. There are enough hypes and bubbles — remember the dotcom 'new economy'? blockchain? NFTs? — to illustrate that absolute certainties do not exist outside of logic and math and our convictions often blind us for reality. It is therefore important to keep your eye on the ball as much as possible.
To help with that, a while back I promised to create a presentation for a conference that would enable non-technical people to understand LLMs well enough that they can estimate if use cases are realistic or nonsense. That made me dig into what was already available helping us to understand the potential of Generative AI (GAI), Large Language Models (LLMs) in particular.
I found YouTube and blogs and (scientific) articles galore. But most of these fall into two categories:
In-depth technical: A lot of focus on the details of the calculations that happen in the 'transformer architecture' (Google's 2017 breakthrough that made these large models possible). You'll learn about feedforward networks, matrix and vector calculations, multi-head attention, softmax, and so forth. These are factual elements, but they are largely irrelevant details for the understanding people should have;
(Imagined) Use: A lot of focus on how these systems will produce a revolution in work and society. These address the organisational or societal effects, but their link to actual reality of what these models do is weak.
I noticed that there was a gap between the technical and the use side.
And what is more, I found that both 'in depth' and 'use' stories generally ignored two aspects that are essential to understanding what these systems do and are capable of. Both are what Terry Pratchett has labelled 'Lies to Children'. A Lie-to-Children is a using a 'good enough' metaphor or simplification. For instance, when we learn about atoms when we're around 10-12 years old, we're often told the nucleus is 'like the sun' and the electrons 'like planets whipping around it'. At that point, the metaphor is useful, even if it is technically false. As a child, the metaphor often leads to ideas, such as that our solar system may be an atom at another scale, or that the atoms are solar systems with tiny people living in them. Metaphors and simplifications are useful, but they can lead us astray when taken as fact.
So, I decided to create an explanation that focused on giving people an understanding of 'how LLMs work' not technically, but more functionally (closing the 'gap'), and clear up these Lies-to-Children while I was at it. For the whole story, see the 40 minute presentation itself on YouTube. Two key elements are repeated here (without all context):
The simplification that misleads us
The first simplification comes from how we interact with these LLMs, specifically ChatGPT because that is the one most people know. What we experience is a conversation, e.q. with questions from us and replies by GPT. But that is not what is happening. To illustrate, we take a very simplified example. I ask ChatGPT "What is the sun?" and it answers "A star". Step by step, what happens is:
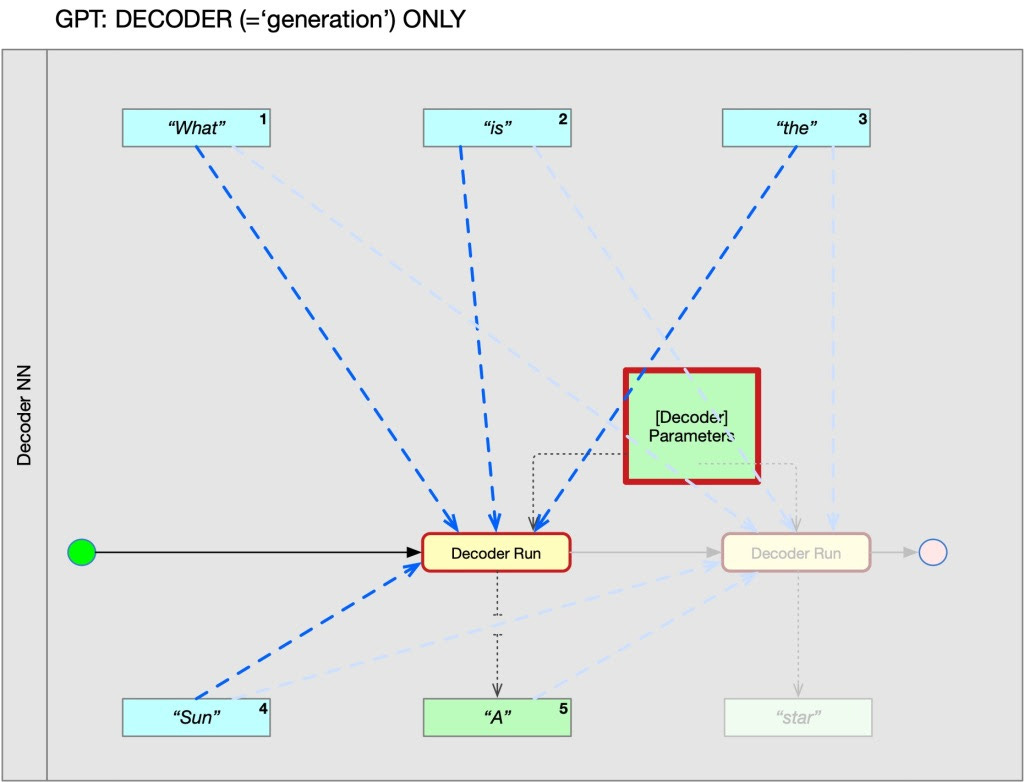
STEP 1. The GPT engine is run once. This single 'run' takes the sequence "What is the sun?" and it produces a single 'word': "A". It does this by using a gigantic 'formula' with 1.75 billion parameters. The input of that formula is that "What is the sun" sequence, where every 'word' in that sequence is represented by roughly 12,000 parameters (an 'embedding') plus a value for its 'position' in the sequence. GPT calculates what the most likely next 'word' is out of a vocabulary of roughly 100,000 'words'. In this case, that most likely next word is "A". Another likely candidate was for instance "Our".
STEP 2. The system adds this "A" to the sequence. The input of the next run becomes "What is the sun? A"
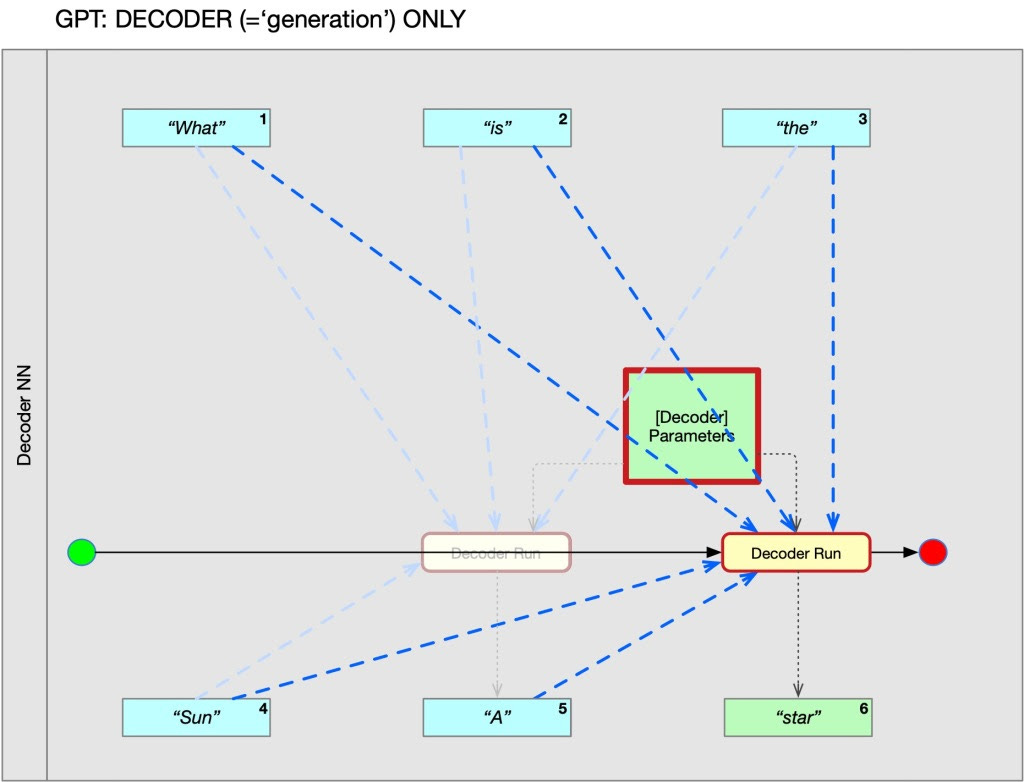
STEP 3. A repeat of STEP 1. The blue arrows represent the 'attention mechanism'. This simplification omits how GPT stops generating (see below).
This process is called 'autoregression'. So, while you experience a prompt-reply sequence, GPT simply experiences a sequence that consists of 'everything that has gone before', it calculates the most likely next 'word' from its vocabulary, adds that to the end and repeats. It stops this process when the most likely next 'word' produced is a so-called <END> token — the 'vocabulary' is not just words. So, while you experience a conversation, GPT only calculates 'most likely next words' from what has gone before and repeats that as long as no <END> token has been generated. In an image:
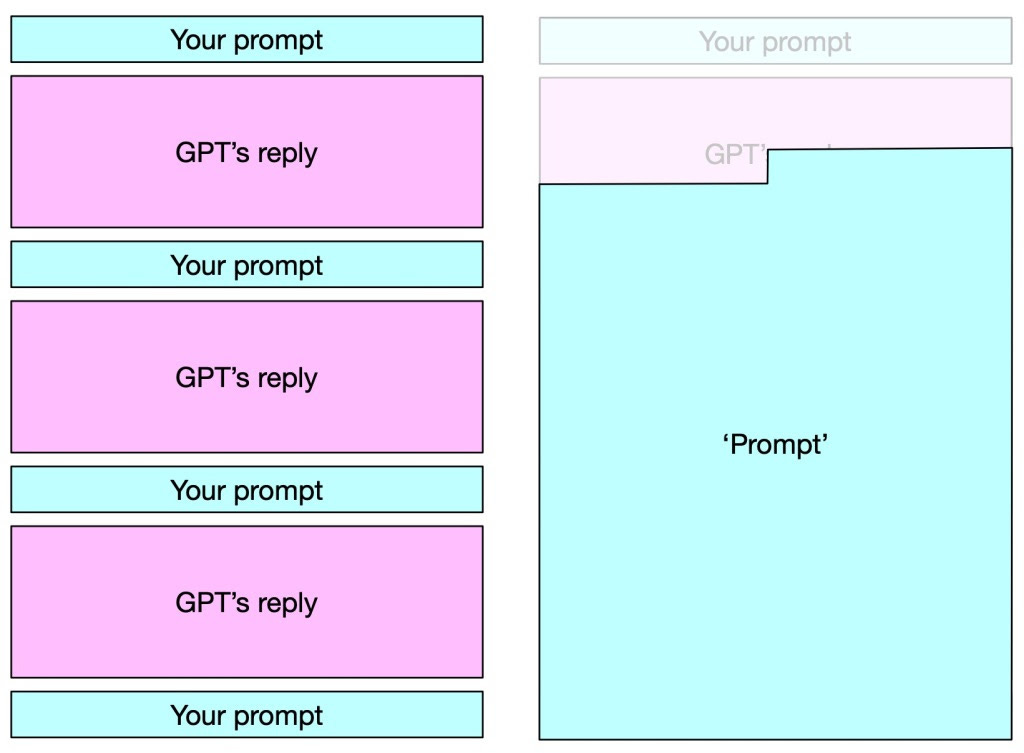
Embeddings and autoregression are elements of LLMs that every LLM engineer knows, but it is taken for granted. It is hardly ever mentioned.
The Lie-to-Children that misleads us
The second Lie-to-Children is that GPT works with words. One of the technical elements of LLMs is the 'attention mechanism', which is part of the 'transformer architecture', and that is about 'paying attention to what has come before'. A famous early example of that 'attention mechanism' is this:

But the example (and every example directed at a general public I have seen) is misleading. That has to do with the elements that GPT actually works with. Take the following silly sentence:

But how GPT and friends hack it in pieces, each of which gets a 12000-parameter 'embedding' (so the big formula has something to calculate with) is like this (taken from OpenAI's own public tokeniser):

GPT doesn't work with (the ~12,000 parameters representing) 'paucity', it works with (the ~12,000 parameters representing) 'auc', or 'p', or 'ity'. It works with 'incap' and 'acity'. Its 'don' is a meaningless fragment, it has nothing to do with an Oxford 'don', or a mafia 'don', or 'donning your jacket'. The same (for us) 'meaningful element' (take 'inoperative') may even be hacked into different fragments.
So, when GPT calculates, it doesn't calculate with anything that has any relation with what is — from a human perspective — 'meaningful'. A (fake) self-attention (how elements within a sequence are related to one another) example could look like:

The sequence is "Overpythonisation leads to incapacity." GPT works with relations between 'over' and 'acity', or 'acity' and a dot. The 'vocabulary' is mostly a vocabulary of meaningless fragments. This enables it to generate correct grammatical patterns very well, but with regard to meaning and correctness of what is produced: not so much — which is why the correctness of LLMs is such an (unsolvable by scaling) problem. So, a sequence of multiple token-generations could run like this:

When people explain LLMs, they never include this 'tokenisation' part (except when talking about what it costs to use, because that is when we users experience them). And I can understand it, because it makes explaining much harder. Even the scientific papers contain examples that are word-tokens only, not fragment/subword-tokens. It's just easier on the reader. It's a convenient and useful 'Lie-to-Children'.
It gets even more clear when you look at how GPT handles numbers. Here is how it tokenises some numbers:

These too, are simple text fragments represented by an embedding of roughly 12,000 values, and are handled as such. So the fact that GPT can produce correct results through this mechanism that has nothing to do with understanding numbers, addition, etc. is actually surprising. Here is a correct answer produced by GPT (shown tokenized):

But make it a little bit harder and GPT falters:

Does this matter?
The question of course is: does it matter that this is how LLMs work? They're still very impressive systems (I agree), after all.
The answer is: yes it matters. The systems are impressive, but we humans are impressionable. We see results that reflect our own qualities (such as linguistic quality), but in reality this quantity has its own quality. And in this case, no amount of scaling is going to solve the fundamental limitations. Simply said: guessing the outcome of logical reasonings based on word-fragment statistics is not really going to work.
We also talk about these systems using words that have a meaning when used in the context of humans, such as 'learning' and 'understanding', but that do not necessarily have the same meaning in this context (as Uncle Ludwig would have it: we are being 'bewitched by language').
Sam and his fellows are holders of deep convictions. They were overwhelmed by the effect of scaling their transformer model and became convinced AGI was within reach. The past year has given many hints that some of OpenAI's people are in the process of realising this is not the case, from Sam's statements to actual technology (see talk).
Psychology teaches us that 'deeply held convictions' are not friends with realism and trustworthiness of observations and reasonings. We — all of us — see above all what we want or expect to see. We crave positive reinforcement. It is a fundamental human property. Therefore, when discussing artificial intelligence, maybe the most important subject is human intelligence, and the observation that we think our convictions come from our observations and reasonings, while the reverse is probably more the case than we will comfortably accept.
In the meantime, we need to be very careful with what we assume to be true and keep looking at what really is going on.
Links
The original talk (this has lots more than has been described here, such as 'will further scaling or fine-tuning help?')
An article showing how the attention mechanism creates 'errors' and why these aren't 'errors' at all (also based on that talk)
An article discussing the role of human convictions
About
Gerben Wierda is a Lead Architect for APG — a not-for-profit fiduciary / collective pension fund manager that manages ~600 billion euros and the pensions of ~4.5 million participants. Note: his views are his own and not APG's.He holds a M.Sc. in Physics from Groningen University and an MBA from the Rotterdam School of Management/Erasmus. He has worked in complex IT all his professional life. Long ago he worked a while for a Language Technology firm that was one of the firms that pioneered statistical methods for language. He publishes a blog and has written two books (of which one is of interest to a more general audience).
Gerben Wierda (LinkedIn)
R&A Enterprise Architecture (main site)
Book: Chess and the Art of Enterprise Architecture (general audience)
Book: Mastering ArchiMate
This article is also part of the Understanding ChatGPT and Friends Collection.
Thanks all, and thank you again, Gerben. Very helpful.
Erik J. Larson
Thank you, Erik and Gerben, for a beautifully explained and elaborated piece. For a (passably!) numerate layman like me, it was engaging and very interesting. It also provided a lot of detail and context, which helped to “flesh out” the intuitive misgivings I’ve had, arising from the disconnect between hyperbole and actual “product”.
I’ll be watching with interest as we continue, as a society, to obsess over our “flawed mirror”.
Thanks so much for this. I have been engrossed as of late in the discussion of how AI will change healthcare, and the conviction, to use your apt word, reminds me of speaking to a group who recently converted to a new religion—true believers, to borrow Hoffer's parlance.
This video, along with Erik’s work, is so important in building a cogent counternarrative built on more than cynicism. I especially appreciated the quotes below, which acknowledge LLM’s benefits but also warn that decisions have consequences, as inertia and pain of “sunk costs” can prevent future change.
“…My advice would be: to concentrate on establishing realism about the use cases….”
But,
“If you wed yourself to these kinds of huge systems, you've actually really fixed yourself to something which is very hard to change.”
Thanks again for the post.
Alan